Embodied Intelligence
引言
具身智能(Embodied AI)强调机器与物理世界交互的重要性,旨在通过促进软硬件一体化智能体的环境适应性学习和智能行为的演化,解决更多智能系统在现实应用中的问题。这一理念促使研究者设计出能够自主学习和适应环境的高度复杂智能系统,使AI研究从纯数字世界的存在跨越到一个能够在物理环境中主动作用和感知的新范式。
目前的非具身学习一般采用“大规模无监督训练+小样本有监督微调”范式,训练得到的模型直接部署到不同的硬件环境,算法的学习独立于硬件环境而存在,其性能表现取决于模型的泛化能力。具身学习则强调通过“大模型”、“基础模型”或“世界模型”范式得到常识表征,在具体场景中通过具身实体、智能算法、环境的相互作用(即生理、心理、物理的三元交互)实现自适应进化,完成智能体对应用环境的自主适配。
具身智能概述与分析
发展历程
随着AI与机器人技术的飞速发展,具身智能概念近几年备受学术界和产业界关注。智能体作为人工智能领域的核心概念之一,是指能够感知环境、进行推理并采取行动的智能系统。智能体既可以是机器人等物理实体,也可以是软件程序、数学模型等形式的虚拟体。一般地,具身智能特指拥有物理实体的智能体,其可以通过与环境进行情景化的交互,主动获取物理世界的真实反馈。 从历史发展脉络出发,具身智能发展分为早期阶段、具身认知提出阶段、深度学习与强化学习阶段、现代发展阶段:

(1)早期阶段。具身智早期的研究主要集中在符号处理和逻辑推理。机器人学开始起步,但主要关注的是工业自动化和简单的任务执行。1950年,英国计算机科学家Tuing开创性地提出“图灵测试”概念,他认为如果一台机器能够与人进行自然的对话,并且无法被人类辨别,那么这台机器就可以被认为是具有智能的。“图灵测试”的提出标志着智能体研究的开端,为后续研究奠定了坚实的理论基础。20世纪60和709年代,智能体研究取得了一定进展。知识表示和推理成为AI研究的主要方向,但这些方法通常依赖于预先定义的规则和模型,缺乏对环境的动态适应能力。
(2)具身认知提出阶段。1986年,美国计算机科学家Minsky首次提出了“Agent”概念,将逐渐构成人类心智或其他认知系统的简单个体环节定义为智能体,对后续研究产生深远影响。1990年,被誉为“机器人教父”的Brooks创立iRobot公司,提出“行为主义机器人”概念,促进了具身智能技术的广泛应用。1993年,Dennett提出了“具身认知”(Embodied cognition)的概念,强调智能体的认知能力与物理实体和环境互动密切相关,这一理论挑战了传统的符号主义认知观,认为智能不仅仅是大脑的产物,而是实体和环境共同作用的结果。
(3)深度学习与强化学习阶段。强化学习强调,机器人可以通过与环境的互动不断优化自己的行为策略。在这个阶段,多模态传感器技术的发展使机器人能够获取更丰富的环境信息,如视觉、听觉、触觉等,为具身智能提供了强大的工具。这一阶段的具身智能已经可以被较为详细地分为多模态感知深度学习领域和行为决策强化学习领域。
(4)现代发展阶段。研究重点开始倾向于在多模态感知与融合、行为决策的基础上新增了自主学习与适应、人机协作等。现代具身智能系统通过整合环境感知数据和智能体认知信息,能够在动态和不确定的环境中表现出更高的适应性和灵活性。研究者还致力于实现具身智能系统的自主学习与进化,使其能够在不同任务和环境中持续优化自己的行为。
优势与挑战
具身智能强调物理智能体与环境之间的主动式交互及智能体的自主进化,持续提升智能体的环境适应性和场景理解能力,并实现更加便捷的人机交互。然而,目前的具身智能研究在智能体学习效率、性能、泛化性方面依然存在巨大挑战,如何设计开放场景通用任务的具身智能系统有待深入研究。
优势分析
具身智能视角下的机器人需要全面感知、理解其所处的环境,根据任务需求控制其物理实体、做出决策,并通过与外界环境的交互快速调整其行动,基于持续的交互式学习和经验累积自主进化。在以下三个方面展现了优势:
(1)多感官精准感知与理解能力。具身智能体通常配备有多种传感器,能够更普遍地通过视觉、听觉、触觉等感官,充分感知其所处场景的物理特性和语义信息,从而做出更精准的决策,实现与场景中其他实体的高效协作。通过更为丰富的传感器,具身智能体相较于普通人工智能载体能够感知到更为全面的环境信息,并借助多模态大模型等算法更好地劣迹所处环境及操作者意图。
(2)交互式场景适应与学习能力。具身智能体能够通过姿势、表情、声音、触感等途径与人类及其他物理实体进行交互,并根据环境的变化快速调整自身行为,通过与环境主动交互来更加灵活地适应不同情况和任务。具身智能更加强调智能体在复杂环境中的知识迁移和泛化能力,以及基于具身交互的具体任务调整能力。
(3)智能体持续自主进化能力。具身智能涵盖了对智能体持续自主进化能力的需求,通过物理智能体、虚拟智能体、真实环境间的持续交互,不断提升智能系统对复杂环境的长期适应能力。不同于现有人工智能载体在投入使用后不具备自我更新的能力,具身智能体能够在工作中自主地识别训练数据中未出现的样本,并在其数量积累到一定阈值后实现自我学习与进化,通过持续的知识更新影响决策行为,从而实现具身反馈闭环。
挑战分析
具身交互。目前在具身智能领域通常应用具身模拟器来复制物理世界,以开展特定任务的研究和测试,从而避免现实世界数据收集的繁琐劳动。然而,真实世界中的交互学习挑战以及“仿真-现实迁移”技术方面存在的不足,进一步妨碍了具身智能研究成果在现实世界中的应用和部署。更多物体类型的物理交互和传感模拟技术需要突破。
具身认知。现实开放场景通常呈现数据形式多模态、数据质量不可控、数据分布长尾化、数据特性动态漂移等多源不确定性。人类天然地拥有从外部世界的自然模态学习并基于直觉理解物理世界的能力,这种自然习得的认知能力能够有效地对抗现实世界的不确定性,而目前的具身认知方法还不具备从自然模态中学习到关于世界的结构化表征与抽象的能力。
具身实体。具身智能系统制造所需的机械结构和设备较为复杂,并且通常需要配备大量的传感器和执行器。高昂的硬件设备与软件研发成本成为具身智能机器人大规模应用进程中的障碍。尤其当需要实现高度复杂的运动或操作时,涉及机械设计、工程制造等多方面挑战。
具身智能的一般性框架
具身智能可以被视作由“本体”和“智能体”耦合而成且能够在复杂环境中执行任务的智能系统。相较于传统AI系统,具身智能强调智能系统通过与环境直接交互以更好地适应复杂动态环境,从而在真实的物理环境下执行各种各样的任务。具身智能系统的研发是一个活跃的研究方向,目前飞速进步的传感器技术、机器人感知与运动控制技术、认知推理与大模型技术等都极大地推进和拓展了具身智能系统等设计思路,但当前仍然缺乏对具身智能研究及具身智能系统通用设计方案的讨论。
(1)高度泛化的动态环境全感知能力。具身智能系统需要搭载多种传感器多方位获取周围环境的信息,通过物理实体进行主动式感知,并实现即时的动态信息融合与处理。如自动驾驶汽车通常需要配备激光雷达、摄像头、毫米波雷达等多种传感器,对道路、车辆、行人等各种元素进行准确识别和跟踪;人形机器人则需要利用视觉、触觉、听觉等多感官信息对作业环境进行全面感知。有些感知系统还需要进行环境建模和动态地图更新,在这一过程中集成一些基础模型并融入特定领域知识。此外,不同于传统的环境感知技术,具身智能感知需要与环境实时交互,在不同的环境状态下选择不同的传感方式和感知策略,最大化利用多种传感器和感知算法的优势,适应不同的域分布看,在不同复杂度的场景中实现强泛化、精准、高效的感知。
(2)稳定可靠的决策规划和控制执行能力。具身智能系统本质上要求智能体具有第一人称主动性,通过与外部环境和其他智能体的主动交互,能自主规划、决策、行动。基于多感官环境信息的综合考虑以及“感知-行动回路”,具身智能系统需要理解外界指令、分解任务、规划子任务,根据需求作出合理的决策,并实时控制智能体的行为,确保安全、可靠地完成物理世界的指定任务,同时需要即时调整控制策略和行为方式以应对外界变化,形成一个感知环境、理解外界、建模世界(世界模型)、采取行动、测试验证 并调整模型的整体过程。
(3)长期自主的学习与进化能力。智能体在与外界环境交互的过程中,不断收集新的数据和经验,通过学习和适应,提高自身的性能和智能水平(持续学习?)。结合平行智能与数字孪生的相关思想,可以构建多维度、多层次的仿真系统,在多个虚拟世界中设计和开发具身智能算法,使其能够在虚拟环境中进行大量的学习和训练,并将其迁移到真实世界,提高具身智能系统对动态开放环境的适应能力。
研究的关键问题
“感知-模拟-执行”一体化机制
在具身智能范式中,智能体被看作一种行为的主体,从类人的角度来看,具身智能体应当是具有动态自适应环境能力、自身想象力、自身行为模式的个体或群体。
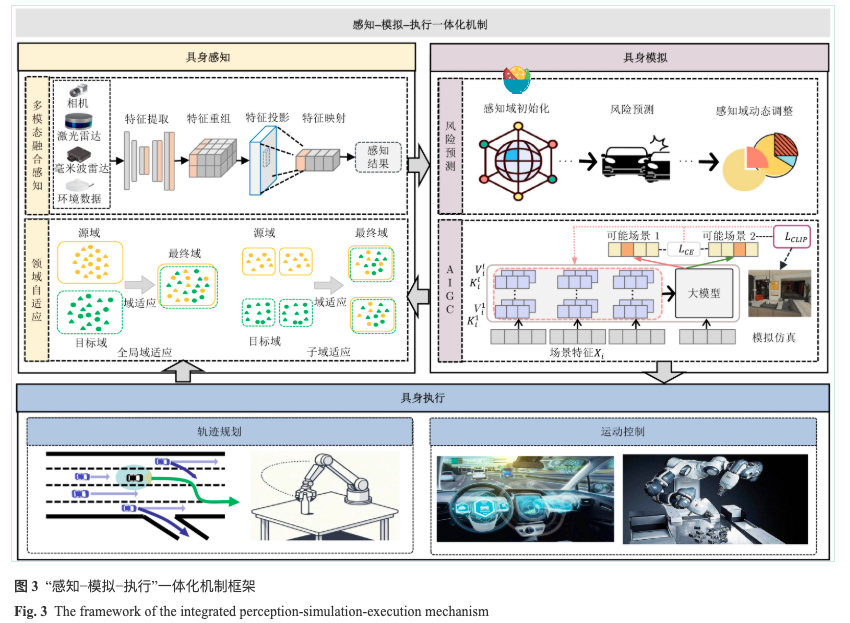
对于具身感知阶段,需要利用多感官、多源异构的环境交互信息,因此多模态融合感知和领域自适应是具身感知模块的重要组成部分;在初步感知结果之后,具身模拟阶段可以利用生成式AI、大模型等技术,模拟将采取的行为,并推理可能的未来情景,并进行风险预测,判断是否执行该行为或反馈至感知算法进行感知域与行为的动态调整;具身执行阶段则通过智能体发出的指令对本体进行控制与决策,如移动机器人轨迹规划、运动控制等。目前,在以自动驾驶为代表的移动机器人领域中已涌现出一批感知-规划端到端的研究成果。
具身感知关键技术
相较于传统感知方法,具身感知强调智能所获取的信息是基于环境交互的全方位信息,不仅来源于视觉、听觉、触觉等多传感器等输入,还依赖于具身交互下所获取的场景状态信息,并在不同的环境条件下均可获得稳定可靠的感知结果。因此,多模态融合感知和领域自适应式不可或缺的关键技术。
多模态融合感知
多模态融合感知方法将来自不同传感器或数据源的信息融合在一起,通过不同传感器的优势来弥补单一传感器的局限性,从而提供更加全面和准确的感知结果,被广泛应用于3D目标检测和多目标跟踪等任务中。但现有的多模态融合感知算法对多感官数据的利用并不充分,同时与动态神经网络的结合仍处于探索阶段,如何实现真正的具身感知有待深入研究。
领域自适应
领域自适应是与机器学习和迁移学习紧密相关的领域,其基本思想是通过学习源域与目标域之间的差异,实现从源域到目标域到迁移。源域和目标域可以是不同的数据集、不同的任务或不同的场景,现有的领域自适应方法可分为数据优化方法和模型优化方法两类。
数据优化方法分为基于伪标签的自训练、图像翻译和域随机化。基于伪标签的自训练时一种同时从无标签数据和标签数据中学习的监督范式,模型首先通过标记数据进行训练,将模型对目标域数据的高置信度预测视为伪标签;图像翻译方法例如CycleGAN,将目标域图像映射到类似源域图像,有效降低了图像信息的分布差异;域随机化方法通过创建各种具有随机属性的模拟环境,去除模型对源域特定风格的依赖。
模型优化方法分为域不变性特征学习、均值教师机训练和图推理。域不变性特征学习通过在目标检测模型中引入域判别器,从而进行对抗训练;均值教师机训练方法克服了时序集成的低效,利用无标签数据和平均模型权重加速教师-学生机之间的反馈循环,从而提升精度;图推理方法建模图像内多个对象之间的相互关系,在目标检测任务中有独特优势。
具身模拟关键技术
具身模拟阶段强调智能体从“场景感知”到“情境认知”的能力,即能够充分理解当前环境,并融合轨迹预测、行为预测、大模型等多元技术,推理或预判未来时刻的种种情况,深入洞察智能体可能面临的风险,为智能体提供及时反馈以引导智能体行动规划并动态自适应环境变化。
风险预测
风险预测在具身模拟阶段发挥重要作用,通过对当前环境及未来时刻的情况进行预测,结合轨迹预测与行为预测等多种方式,实现对智能体的风险感知,确定重点区域,反馈至感知系统并作出相应决策。
具身模拟阶段需要结合多种预测方式感知智能体行为风险,通过模拟智能体在不同环境中的行为模式,确定潜在的风险感知域,并预测智能体在特定环境下可行的反应和决策,即实现从“场景感知”到“情境认知”, 为具身执行提供重要的依据。
AIGC
AIGC相关技术和物理仿真环境能够为具身模拟提供真实物理世界的替代,极大加快具身学习的速度。如何缩小真实世界与仿真模拟环境之间的差距一直是AIGC领域重点解决的一个问题,解决方案主要包括基于学习的AIGC方法以及基于物理的AIGC方法。
基于学习的AIGC指利用深度学习技术实现内容生成,常见方法包括扩散模型和Transformer架构模型等。扩散模型通过逐步添加噪声并学习去噪过程来生成图像,Stable Diffusion在这一过程中加入了稳定性和高效性的改进,使得模型在生成高分辨率图像时仍能保持较为真实的生成效果。Imagen则通过结合扩散模型与大模型预训练的语言模型,实现了文本描述到高质量图像的转换。Transformer模型利用自注意力机制,可以处理长距离依赖关系,因而在文生图任务中表现出色。
基于物理的AIGC通过将物理先验知识引入生成框架,使预训练的模型生成的内容更接近于真实世界。这种方法主要结合了物理模型与机器学习技术,以确保生成的内容不仅在视觉上逼真,而且符合现实世界物理规律。如GIRAFFE算法通过引入物理先验知识并结合递归反馈机制,从而能够生成复合物理规律的三维场景,并在处理复杂的光照和材质时表现优异。物理先验知识的加入也极大地提升了智能体的预测模拟能力,如高斯-粒子双重表示法,将视觉与物理信息结合,从而使机器人在与现实世界交互时能够准确预测未来状态。
目前较为主流和前沿的技术一般考虑上述两者的结合,利用模型去学习不同的物理属性和物理规律,将基于AIGC的仿真引擎和表征具身常识的基础模型接入智能体,不仅使得智能体能够与环境有效交互,还能够在无需额外数据和训练的情况下完成各种任务。
具身执行关键技术
如何将具身智能体对外界环境的感知和认知结果转化为行动是具身执行阶段的核心。具身智能体的行动主要可分为移动(如智能体轨迹规划与优化)和操作(如物体抓取与操纵等执行部件的运动控制)。
具身学习与进化研究的关键问题
具身智能强调智能体以模拟生物形态的形式与复杂环境交互各类信息,同时利用这类信息实现自身的更新优化以达到长期自主工作的能力。因此,除了感知与执行外,智能体的学习与进化研究同样中阿哟。根据形态-行为-学习这一具身智能体系理论,智能体应当通过学习进化提升行为、优化形态。学习优化是进化的基础,而进化遗传是学习的体现。通过自主感知获取环境的各类信息,智能体在优化自身行为策略的同时产生形态优化策略,这一过程可以被视为寻找在当前环境下执行特定任务时的最优解过程,将泛化性强的行为和形态策略作为预训练模型或先验知识共享给其他智能体, 在新的智能体上继续学习优化使其适应更复杂的环境或任务要求,实现学习与进化的共同促进。
总结与展望
虚实融合数据智能
在真实世界中采集具身感知和学习相关的数据集存在较高代价,尤其是某些特殊场景或任务(如自动驾驶长尾场景)容易不可避免地引入成本高昂甚至危险的实时交互,难以规模化。目前,相关研究人员聚焦于在虚拟仿真系统中设计和开发具身智能算法,然后将其迁移到现实物理世界,如具身导航[143]、具身问答[144]、智能体/机器人操作任务[145−146]等。 针对不同的环境或任务需求,已涌现出多种虚拟仿真平台、数据集、任务和学习框架, 为具身智能研究提供有效的数据平台(也可以称为具身智能模拟器). 如面向具身导航任务的iGibson[147−148]系列、Habitat[149−150]、MultiON[151]、BEHAVIOR[112−152], 面向具身问答的ALFRED[144], 面向智能体/机器人操作任务(如家具重排、物体抓取等)的AI2-THOR[153]、ThreeDWorld[154−155]、Habitat 2.0[156]等虚拟仿真环境. 然而, 目前的具身智能模拟器在逼真度、可扩展性和互动性等方面仍然存在较大挑战, 进一步妨碍了具身智能研究成果在现实世界中的应用和部署. 此外, 只有少数具身智能模拟器[153−155]配备了多智能体设置, 因此针对多智能体特性的研究任务仍然较少.
总体来看, 高质量的具身任务数据集、更逼真高效的具身模拟器、人类示范数据的有效利用以及更有效的虚实迁移技术对于具身智能的物理实现有着重要意义. 如何利用计算机图形学、虚拟仿真引擎、计算机视觉等领域的前沿技术提升虚拟数据平台的逼真度, 以及引入更多的现实世界数据集并有效利用人类演示数据来训练和优化机器人系统, 探索更多虚拟环境与真实环境之间的迁移及域适应技术, 是未来具身智能发展需要考虑的重点问题.
基础模型与基础智能
自以GPT4等为代表的多模态基础模型发布以来, 国内外掀起了一波新的研究热潮, 并逐渐形成了“百模大战”的井喷式局面. 基础智能可以理解为通过将更深层次的智能融入基础模型中, 进一步提升模型的智能水平, 以便在智能决策与推理等方面展示出更高的性能. 首先, 在通用基础模型方面, 国内各具特色的大模型层出不穷. 例如, 在工业界, 百度、阿里云、华为、腾讯、科大讯飞、月之暗面等相继提出了各自的通用大模型; 在学术界, 清华大学、北京大学、中国科学院自动化研究所、北京智源研究院、上海人工智能实验室等也纷纷提出了具有创新性的大模型. 除了研究通用基础模型外, 国内已有一些研究开始探索如何将基础模型与特定领域相结合, 构建特殊场景下的工业基础模型. 比如, 基于39年的全球气象数据, 华为盘古气象基础模型开发了实时气象预测系统, 在预测精度上超越了传统的基于数值的预测方法[157]; 中煤科工西安研究院构建了地质垂直领域的基础模型GeoGPT, 实现了地质行业知识的问答; 华南理工大学构建了医疗模型扁鹊BianQue, 用于生理健康诊断问答. 因此, 通过引入基础模型和基础智能, 处于复杂CPSS (Cyber-physical-social systems)[158−159]环境中的具身智能可以进行更加准确的感知、推理及决策, 逐步实现从“被动控制”到“主动感知”的范式转移.
总体来看, 复杂环境理解与认知能力、强适应可扩展的基础模型架构、安全可靠的具身智能体运行模式对于具身智能系统的实际应用有着重要意义. 如何提升具身智能体对复杂环境中长期任务的理解, 如何提高多模态具身智能体在复杂现实环境中的适应性、决策可靠性和泛化能力, 并保证具身智能体能够以可解释、可交互、可持续的方式在现实环境中运行, 如何利用基础模型及基础智能来构建具备强大感知能力和大量世界知识的高效智能机器将是未来研究的关键问题.
数字孪生与平行智能
对于具身智能来说, 如何与包含复杂社会因素的环境进行高效交互是其实现“自我进化”的重要手段. 在传统的基于数字孪生的物理环境建模中, 其主要目的在于实现对物理空间中实体的高度数字化, 完成物理空间与虚拟空间的1:1映射. 但是, 由此构建的虚拟系统并不能灵活地应对物理世界的各种变化, 具有一定的局限性. 为了解决上述问题, 平行智能理论将成为具身智能未来研究的主要内容. 平行智能理论[160−162]已经被成功应用到包含交通、制造、医疗、农业等在内的各个领域[163−170]. 平行系统可以理解为由某一个自然的物理系统和对应的一个或多个虚拟或理想的人工系统所组成的共同系统[171−172]. 通过构建物理空间与虚拟空间的N:M映射, 平行智能理论可以通过ACP (Artificial systems, computational experiments and parallel executions)方法实现对包含社会因素的复杂环境的高效管理与控制. 区别于传统的特征工程, 在构建人工系统方面, 平行智能理论采用场景工程(Scenarios engineering)建模的方法来构建更加具有可解释性的人工系统[173]. 基于I&I (Intelligence & index)、C&C (Calibration & certification) 和V&V (Verification & validation), 场景工程建模可以理解为在特定时间和空间内对相关场景和活动的综合反映[174]. 此外, 通过平行执行, 人工系统与物理系统能够实现虚实交互和闭环反馈, 不仅提高了复杂物理系统的决策水平, 还为应对未来场景的发展和变化做好了充分的准备[175].
总体来看, 在具身智能的研究中引入平行智能理论, 不仅可以构建更加可靠和可解释性的人工系统, 为其应对复杂多变的物理环境提供有力的技术支撑, 还有助于促进具身智能与周围环境的交互和学习, 大幅提升具身智能系统的感知与决策能力. 进一步地, 如何考虑以增量学习、在线自适应和人在环路学习为代表的持续学习技术, 以减轻灾难性遗忘并增强系统稳定性, 从而构建更加可信的具身智能系统, 如何建立和统一具身智能任务的评估基准, 以及如何全面综合地衡量机器人执行长期任务的成功率和智能系统的能力, 也是未来有待探索的重点问题.
Enjoy Reading This Article?
Here are some more articles you might like to read next: